CPLIP: Zero-Shot Learning for Histopathology with Comprehensive Vision-Language Alignment
CVPR 2024
Sajid Javed1, Arif Mahmood2, Iyyakutti Iyappan Ganapathi1*,
Fayaz Ali Dharejo1, Naoufel Werghi1*, Mohammed Bennamoun3
1 Department of Computer Science Department & C2PS*, Khalifa University, Abu Dhabi, UAE 2 Information Technology University, Lahore, Pakistan 3 The University of Western Australia, Perth, Australia
This paper proposes Comprehensive Pathology Language Image Pre-training (CPLIP),
a new unsupervised technique designed to enhance the alignment
of images and text in histopathology for tasks such as classification and segmentation. This methodology
enriches vision-language models by leveraging extensive data without needing ground truth annotations.
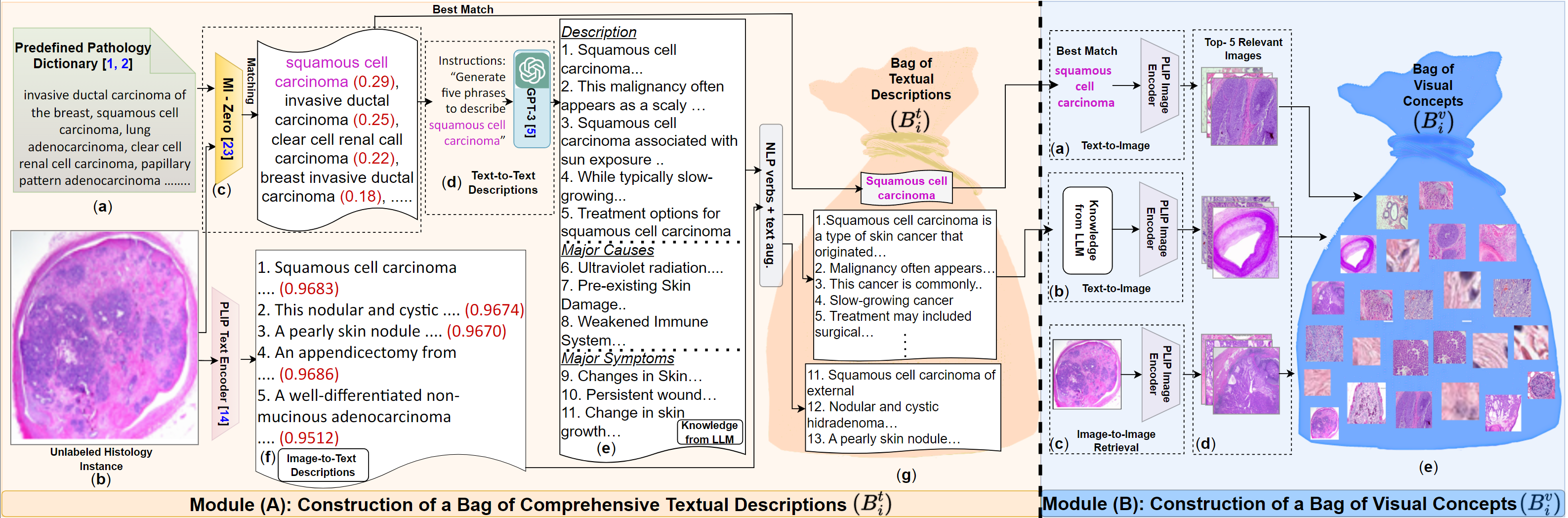
CPLIP involves constructing a pathology-specific dictionary, generating textual descriptions for images
using language models, and retrieving relevant images for each text snippet via a pre-trained model.
The model is then fine-tuned using a many-to-many contrastive learning method to align complex interrelated concepts across both modalities.
Evaluated across multiple histopathology tasks, CPLIP shows notable improvements in zero-shot learning scenarios, outperforming existing methods in both interpretability and robustness and setting a higher benchmark for the application of vision-language models in the field.
The Proposed Model
This work introduces the CPLIP algorithm, which leverages unlabeled histology images and a pathology
prompt dictionary to fine-tune the CLIP model without any annotations. This adaptation aims to enhance
CLIP's performance across diverse histology data, enabling transfer learning for different pathology tasks.
In computational pathology, VL models have evolved from being novel to indispensable,
allowing fine-tuning on smaller datasets compared to VL pretraining. However, the scarcity
of Whole Slide Images (WSIs) and
diverse cancer morphologies presents challenges for zero-shot transfer tasks, such as
patch-based tissue recognition and WSI-level cancer subtyping. Despite this, VL models
have been successfully deployed in classifying and analyzing WSIs, revolutionizing computational pathology.
Textual prompts are crucial for improving VL model performance, but their reliance on single phrases
for each histology image may limit zero-shot classification effectiveness. Introducing richer,
more detailed prompts could broaden VL models' understanding of various cancer types.
Currently, existing histology VL models do not incorporate diverse textual prompts
during training or at the inference stage. Unlike existing methods focusing on aligning
individual textual and visual concepts, our approach proposes simultaneous alignment of
numerous interrelated textual and visual concepts.
Dictionary
The ARCH dataset, the main source of histology image-caption pairs, has limitations as it requires
paired data. To overcome this, we propose a pathology prompt dictionary to extract comprehensive
image-text descriptions.
Our dictionary, curated from reputable cancer glossaries1 &
2, covers a wide range of cancer types and morphologies.
We compared it with another vocabulary, refining it to include 700 terms related specifically to histopathology.
The refined dictionary aims to aid diagnosis by providing succinct prompts for major cancer types and
morphologies.
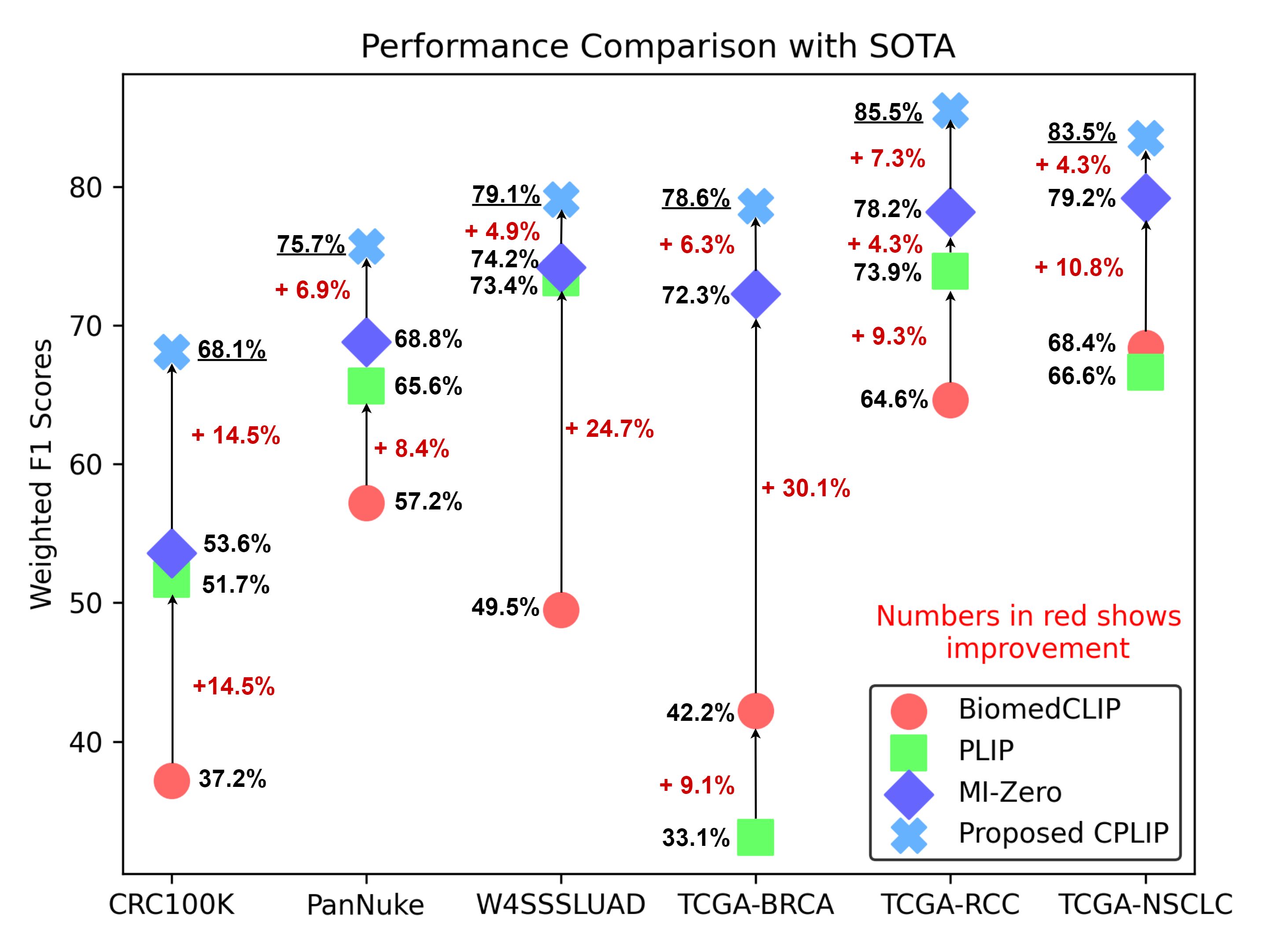
Results
A comparative assessment of zero-shot classification performance is conducted, contrasting the novel CPLIP algorithm with state-of-the-art methods including
BiomedCLIP,
PLIP,
and
MI-Zero.
The analysis, based on weighted F1 scores, illustrates CPLIP's significant performance improvements across six distinct histology datasets.
Citation
If you use the findings of this research in your work, please cite our paper:
@article{sajid2024cplip,
title={CPLIP: Zero-Shot Learning for Histopathology with Comprehensive Vision-Language Alignment},
author={Sajid Javed, Arif Mahmood, Iyyakutti Iyappan Ganapathi, Fayaz Ali Dharejo1, Naoufel Werghi, Mohammed Bennamoun},
year={2024}
}
Contact
For any inquiries regarding CPLIP or to reach out, please feel free to contact
Sajid Javed at {sajid.javed at ku.ac.ae} / Iyyakutti Iyappan Ganapathi at {iyyakutti.ganapathi at ku.ac.ae}.